PROJECT: PlanWithEase
Hello there! I am Jackie. I am currently a student at the National University of Singapore
(NUS) studying Information Security. I love to build application that could simplify our life then break it down to make
it better again!
This portfolio documents my involvement in the PlanWithEase, a degree planner application which is morphed from AddressBook Level 4.
PlanWithEase is developed by my team (consisting of Ahn TaeGyu, Bai YunWei, Ngo Wei Lin, Yeo Cheng Hong and myself) under the CS2113T (Software Engineering & Object-Oriented Programming) module taken in NUS over the span of 8 weeks.
Overview
For this project, we aim to simplify the process of planning a degree, and ensure that the degree plan fulfills the degree requirements for graduation.
With this goal in mind, we developed PlanWithEase (PWE), degree planner desktop application designed to help National University of Singapore (NUS) Information Security freshmen in creating a comprehensive degree plan with ease according to their degree requirements.
We understand that planning a degree is not an easy task,and can be very time-consuming. Further more there are much considerations to make, making it confusing, troublesome and difficult to create the perfect degree plan.
With this goal in mind, we developed PlanWithEase (PWE), a degree planner application designed to help NUS Information Security freshmen in creating a comprehensive degree plan according to the degree requirements effortlessly.
My role as a developer in this project involves designing and write code to enhance our existing find features
which enables our users to do the following:
-
Finding modules with either its name, code or credits.
-
Complex search terms to narrow down the find results.
Understanding This Project Portfolio
The following symbols are used throughout this project portfolio:
|
This symbol denotes information that you may want to take note of when using the application. |
|
This symbol denotes a tip which you may find useful when using the application. |
|
This symbol denotes a warning message which you need to be careful of when using the application. |
Additionally, you may also encounter the following text styles:
-
Commands or parameters will be in this
format. -
Important messages will be bold.
-
Undoable command will be in italics.
-
Keyboard buttons will be referred to as such: F1.
Summary of contributions
This section details the main enhancements as well as other contributions I have made in the project. |
-
Main enhancement: added the ability to perform complex find command
-
What it does: allows the user to find modules via more complex find criteria. Find criteria can be composed from mixed of logical AND (
&&) and logical OR (||), users can optionally specify parenthesis to denote the expression to be evaluated first. -
Justification: With a expected large number of modules available in our application, users needs to be able to find a small subset of modules which are of interest to them. The ability of performing complex find commands give users the flexibility of finding a smaller subset of modules which are relevant to them.
-
Highlights: The algorithm for this enhancement was generalized not only to suit my own features, but also my team mate’s features. My team mate (Ahn TaeGyu) has managed to make use of this generalized class I created for his own features. The implementation of this enhancement required some research on the different ways of parsing a boolean expression, as there are many parsing algorithms available. After deciding on the algorithm to be used, I had to implement the said algorithm in code using an Object-Orientated style, while trying to abstract the algorithm as much as possible as per the requirements of Object-Oriented Programming.
-
-
Code contributed: [Commits] [Pull Requests] [RepoSense Code Contribution Dashboard]
-
Other contributions:
-
Project management:
-
Enhancements to existing features:
-
Sourced for new application icon and update the application accordingly. #110
-
Updated the GUI color scheme. #144
-
Collaborated with a team mate (Ngo Wei Lin) to implement a custom string tokenizer
BooleanExpressionTokenizer, which enables the users to be able to use complex search conditions to narrow down their search when usingfindandplanner_showcommands. (#119)
-
-
Documentation:
-
Community:
-
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users to facilitate mastering of PlanWithEase's features. . |
Finding modules : find 
Having trouble locating the modules you want?
Make use of find command which allows you to find modules that have their names, code or credits matching the given
search criteria.
Command Format: find [name/NAME] OPERATOR [code/CODE] OPERATOR [credits/CREDITS]
When this command is used, the application will display only those modules which satisfy the search criteria.
The following table describes the valid prefixes that you can supply to the search criteria.
Prefix |
Description |
|
Search for any module |
|
Search for any module |
|
Search for any module |
|
Search for any module |
|
Search for any module that is being offered in |
The following table describes the valid operators which you can supply to the search criteria.
Operator |
Description |
Precedence |
|
Logical "AND" operation (both conditions A AND B must match) |
Highest |
|
Logical "OR" operation (either conditions A OR B must match) |
Lowest |
|
Search term surrounded by parenthesis will always be evaluated first. If there is a tie, the logical operator precedence will be taken into consideration. |
N.A |
The following examples describes how you could form a valid search criteria for the find command.
Single Prefix Usage |
Expected Result |
|
Returns modules containing |
|
Returns modules containing |
|
Returns modules having |
If you need multiple prefixes, the following table shows some examples on how it can be done.
Note that you will need to separate multiple prefixes with an operator.
|
You could choose which search criteria having a higher priority by specifying parenthesis |
Multiple Prefix Usage |
Expected Result |
|
Returns modules containing both |
|
Returns modules containing both |
|
Returns modules containing |
|
Returns modules containing either |
Examples:
-
find name/computer
Displays all modules with names containing the wordcomputer(e.g.computerandComputer Security) in the module list.
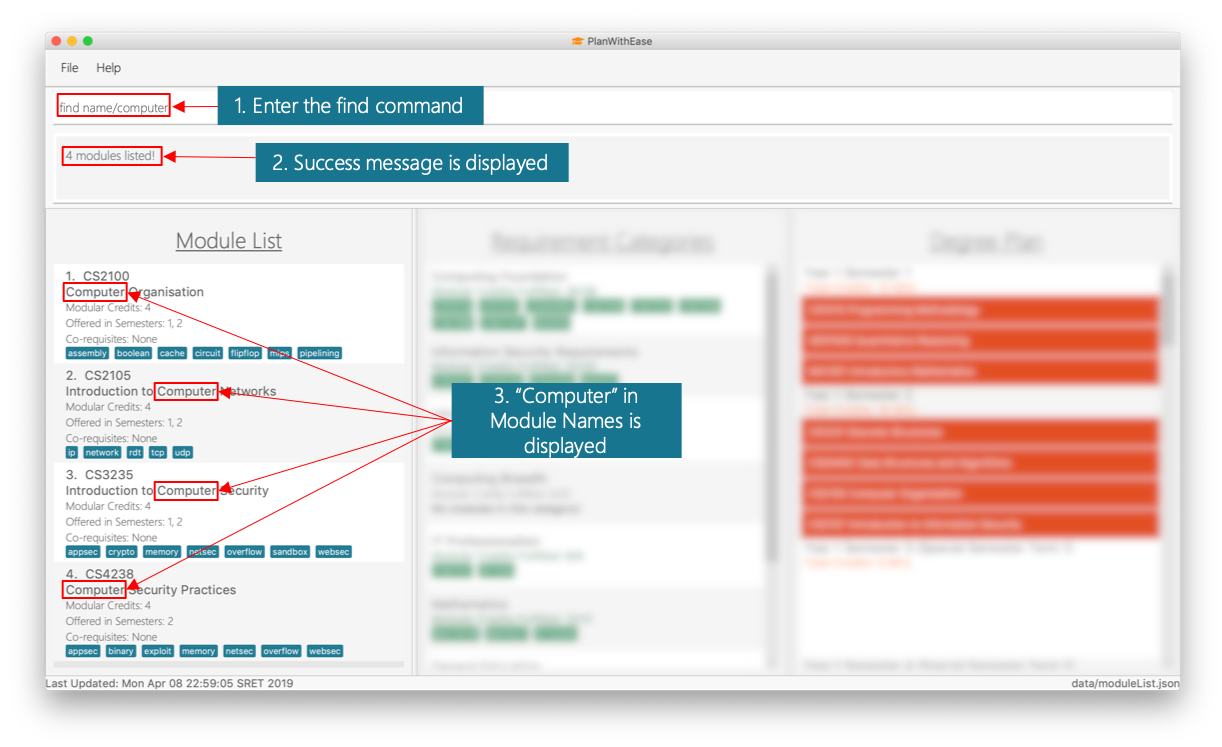
computer-
find name/computer && name/SecurityDisplays all modules with names containing the wordcomputerandsecurityin the module list.
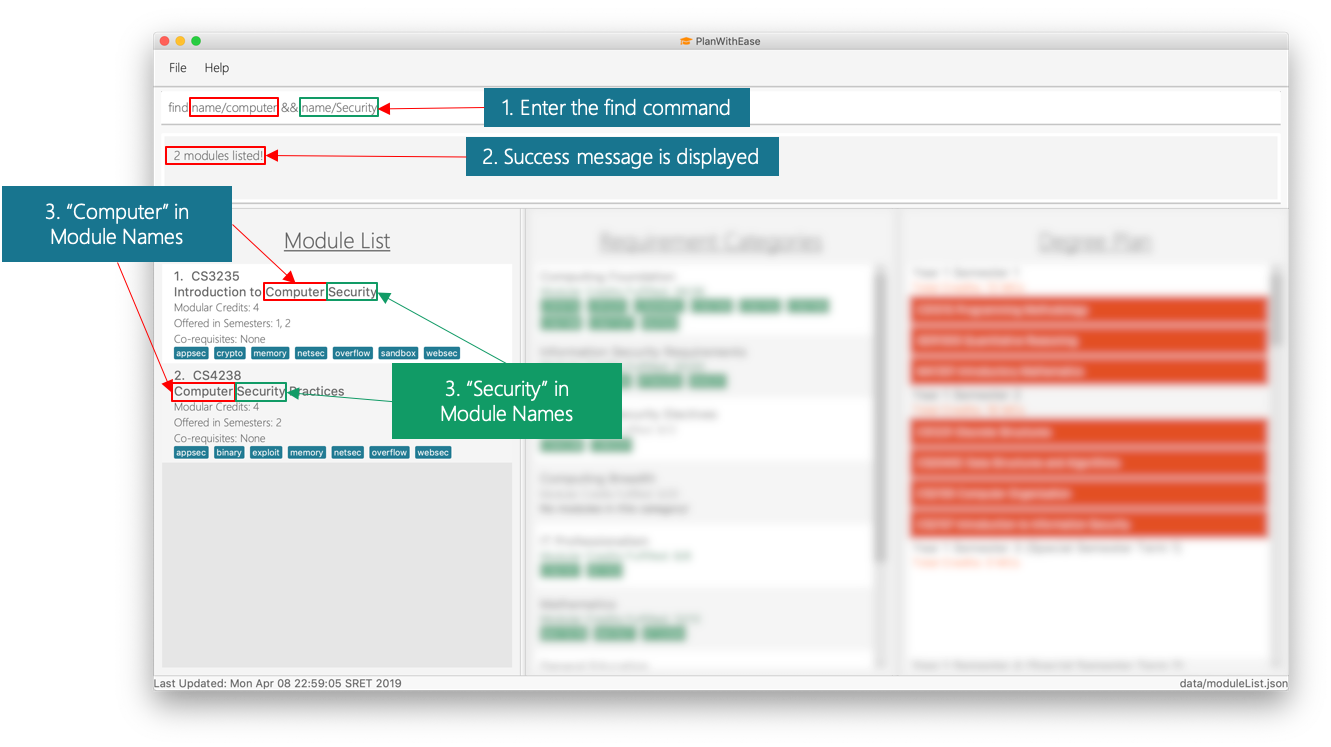
computer and security.-
find (sem/1 || sem/4) && name/Programming
Displays all modules with names containingprogrammingand is offered in either semester1or4in the module list.
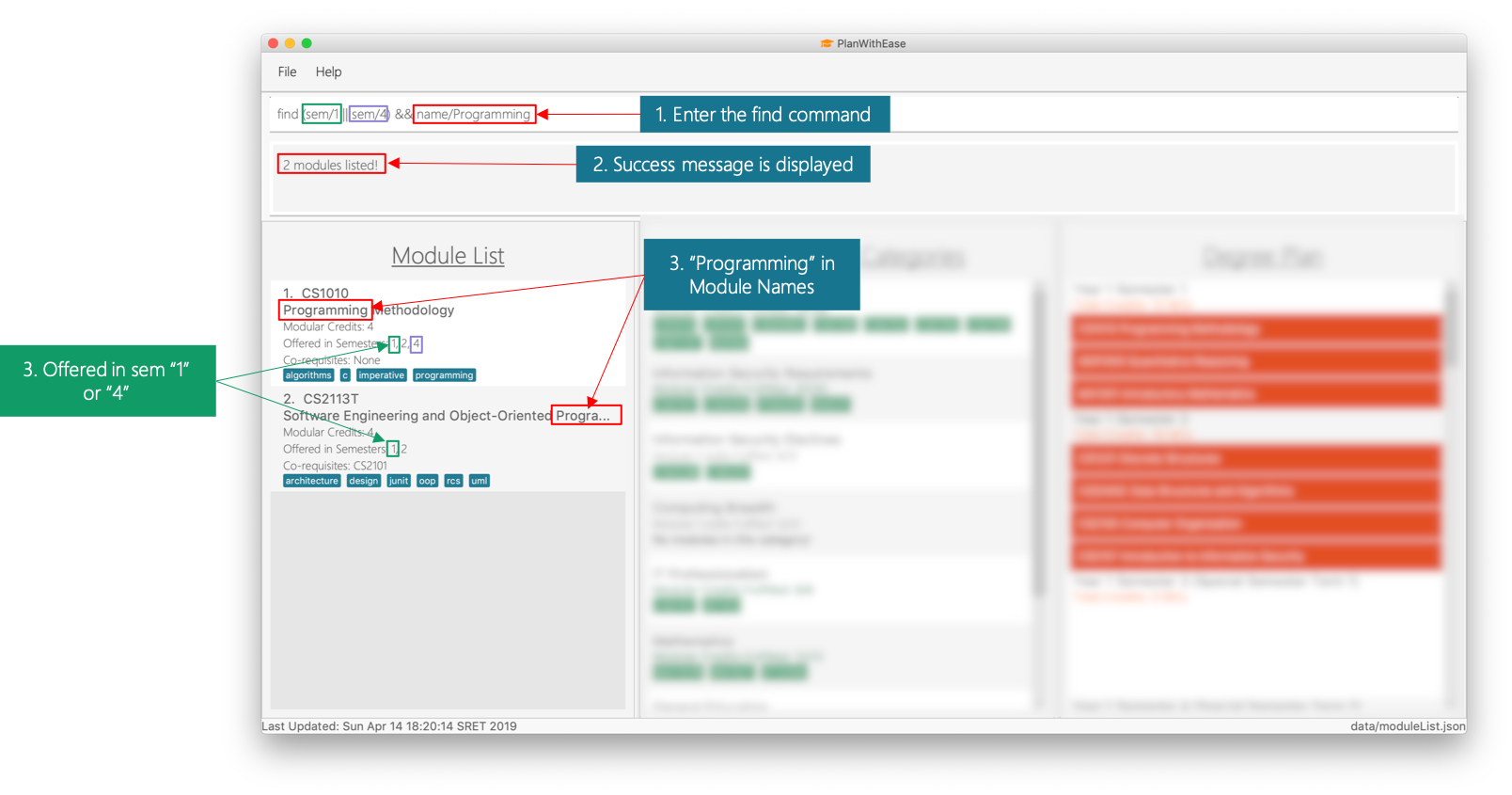
programming and is offered in either semester 1 or 4.|
If you wish to search for module name with exact name Do note that if you prefer to search for module name containing both |
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
Find Feature
The find feature aims to help users to be able to easily locate any modules in our application. With a large number
of modules available to our users, find feature is essential. Currently, the find feature only supports searching
of module’s name, code, credits, tags and the semesters it is offered in.
This section shares the implementation and the design considerations gone through while enhancing the find feature. Details on how the find feature is implemented and how it supports more search parameters are also shared.
Overview
When a user invokes the find command. (e.g. find name/Programming || code/CS1231), the following steps are taken by
the program.
-
Extract out the text related to
findcommand -
Parse the text related to each
PREFIXindividually. -
Return a composite predicate for all attributes.
Step 1 is performed by the ApplicationParser class, and no special actions is needed for the find feature.
Step 2 and 3 are performed by BooleanExpressionParser#parse
The class diagram below shows the different components and constraints for find feature.
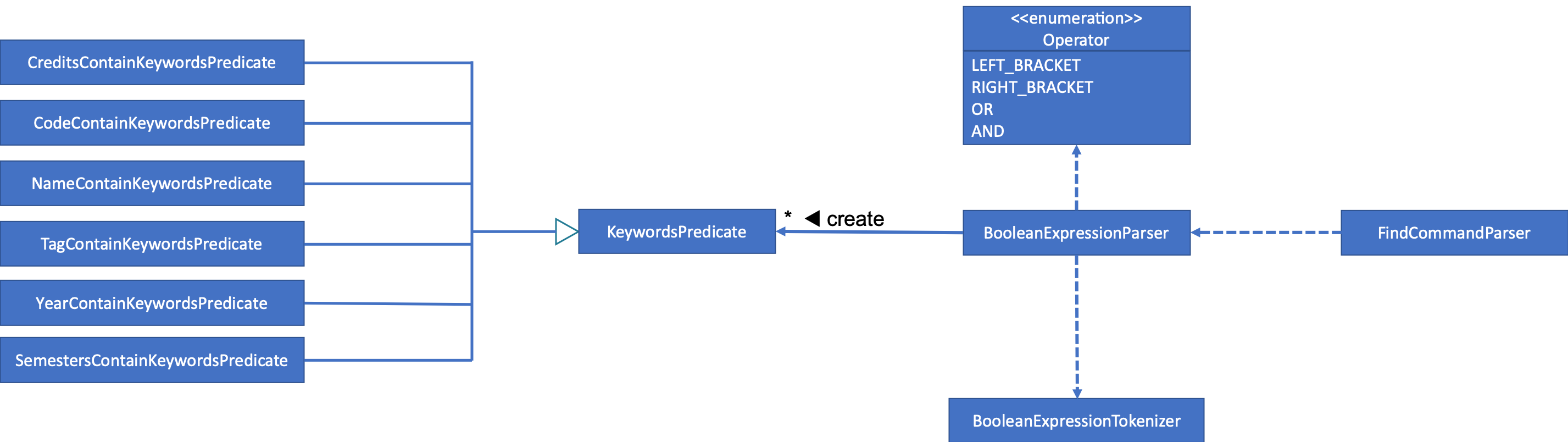
find featureCurrent Implementation
The FindCommandParser parses the strings of arguments provided by the user to retrieve a composite Predicate
which is used by FindCommand. A ParseException is thrown in the case if the input provided by the user does not
conform to the expected format.
The sequence diagram below shows the interaction within the Logic components.
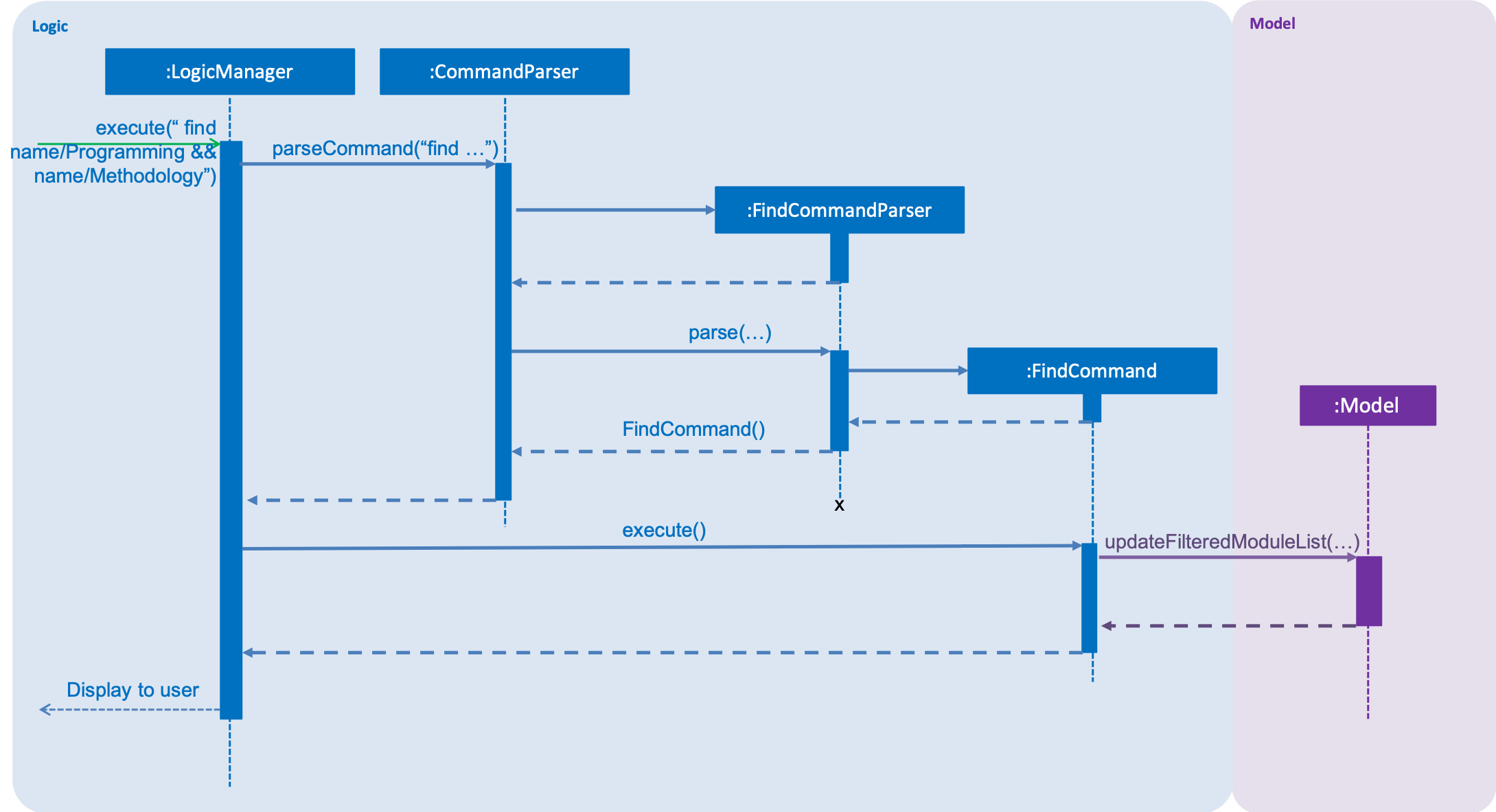
The main implementation of this feature is split into two components. The Tokenizer and BooleanExpressionParser
-
Tokenizerhelps to split the user provided argument into tokens which could be used byBooleanExpressionParser. -
BooleanExpressionParsersimply performs Shunting-Yard algorithm on the boolean expression tokens provided by theTokenizerand maps them intoPredicatewhich could be used byFindCommand.
FindCommandParser calls BooleanExpressionParser#parse which handles the evaluation of the expression.
This process is achieved by the code snippet shown below.
String trimmedArgs = args.trim();
if (trimmedArgs.isEmpty()) {
throw new ParseException(
String.format(MESSAGE_INVALID_COMMAND_FORMAT, FindCommand.MESSAGE_USAGE));
}
Predicate<Module> predicate = BooleanExpressionParser.parse(args, PREFIXES);
return new FindCommand(predicate);To support more parameters for our find feature. You can do the following steps.
-
Create a new
Predicateclass (e.g.NameContainsKeywordsPredicate) and define your expected behaviour in it. -
Ensure your
Predicateclass extendsKeywordsPredicate. -
Update
BooleanExpressionParser#getKeywordsPredicateto handle the creation of thePredicate. -
Update
CliSyntaxon the new prefix you would like for the new parameter. -
Update
FindCommandParserto take in the newPREFIX.
Your new parameter will now be supported after the above steps!
Tokenizer
This is represented by the class pwe.planner.logic.parser.BooleanExpressionTokenizer and is designed to extract
all argument with PREFIX and OPERATOR as a token.
This class is initialized with the input argument and prefixes and can be queried for token multiple times.
Each query will consume the previous token and returns the next available token.
This is similar to how java.util.Scanner works.
Design Consideration
After many rounds of experiment with StringTokenizer that is provided by native Java and ArgumentMultimap.
We found three main issues which could not be satisfied by either StringTokenizer or ArgumentMultimap.
-
ArgumentMultimapdoes not keep track of the order of each delimiter. They will only track if the delimiter exists. -
StringTokenizerhas a default delimiter as a whitespace, although we could change the delimiter and parse multiple delimiters. It does not suit our situation.
e.g.find name/AAAA code/BBBB.
This will return us 1 token.name/AAAA code/BBBB, which we cannot use to check due to the missingoperator.
We need the tokenizer to return us 2 tokensname/AAAAandcode/BBBBin order for us to know that the expression was invalid due to the missingoperator. -
StringTokenizercan take inPREFIXas delimiter, however, this will split the argument (i.e.code/CS1231) into two tokens,code/andCS1231.
Additional parsing is required before we are able to pass it toBooleanExpressionParser. This parsing creates more overhead as we have to ensure that the proper checks are done.
As such, our custom Tokenizer aims to solve these three issues.
The table below shows the differences among our Tokenizer, StringTokenizer and ArgumentMultimap
|
|
|
Respect the order of delimiters. |
Respect the order of delimiters |
Only keep track which delimiters are present. |
Support multiple delimiters. |
Support multiple delimiters. |
Support multiple delimiters. |
Splitting tokens is more flexible |
Only split token based on delimiters |
Does not split into token. |
Operator
This is represented by the class pwe.planner.logic.parser.Operator and defines all valid operators to be used in
BooleanExpressionParser.
The table below shows the valid operators that our application currently supports.
Operator |
Description |
Precedence |
|
Logical "AND" operation (both conditions A AND B must match) |
Highest |
|
Logical "OR" operation (either conditions A OR B must match) |
Lowest |
|
Search term surrounded by parenthesis will always be evaluated first. If there is a tie, the logical operator precedence will be taken into consideration. |
N.A |
To support more operators for our BooleanExpressionParser. The following steps should be performed.
-
Add the operator and give it precedence.
-
Update the mapping between
StringandOperatorinOperator#getOperatorFromString -
Update the logic of the new operator in
Operator#applyOperator -
Update
CliSyntax.OPERATORSto include the new operator.
Boolean Expression Parser
This is represented by the class pwe.planner.logic.parser.BooleanExpressionParser and is designed to map user
provided input into composite Predicate<Module>.
The following table shows the operators currently supported by BooleanExpressionParser(Highest precedence
first).
Operators |
Description |
|
Logical AND of two predicates |
|
Logical OR of two predicates. |
Parentheses ( and ) are also recognized and respected, and they may be nested to arbitrary depth. This is handled by
Shunting Yard algorithm which respects the precedence of each
operators when parsing.
The sequence diagram below shows the interactions between FindCommandParser and BooleanExpressionParser.
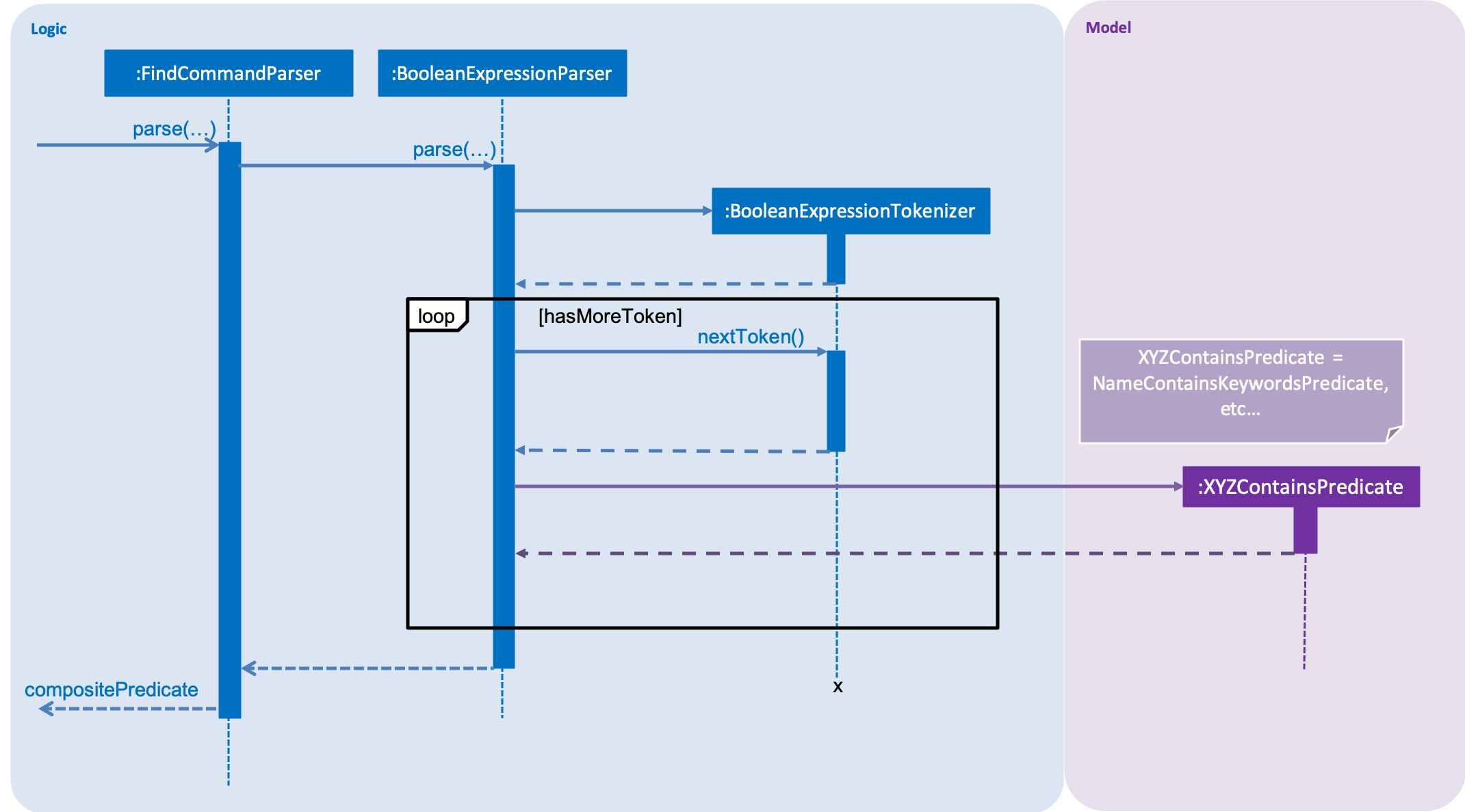
When FindCommandParser receives the provided user argument, it will carry out checks and pass the argument to
BooleanExpressionParser which will initialize a new Tokenizer that extracts the arguments as tokens.
BooleanExpressionParser will create a Predicate based on the Prefix in each token. If the token is an Operator,
BooleanExpressionParser will apply the operator on two Predicate to combine them into a composite Predicate.
|
See Tokenizer for more details regarding the tokenizer. |
The process of how the predicate for each prefix is created is shown in the code snippet below.
ArgumentMultimap argMultimap =
ArgumentTokenizer.tokenize(args, PREFIX_NAME, PREFIX_CODE, PREFIX_CREDITS);
KeywordsPredicate predicate = null;
if (argMultimap.getValue(PREFIX_NAME).isPresent()) {
String nameKeyword = ParserUtil.parseName(argMultimap.getValue(PREFIX_NAME).get()).toString();
predicate = new NameContainsKeywordsPredicate(List.of(nameKeyword));
} else if (argMultimap.getValue(PREFIX_CODE).isPresent()) {
String codeKeyword = ParserUtil.parseCode(argMultimap.getValue(PREFIX_CODE).get()).toString();
predicate = new CodeContainsKeywordsPredicate(List.of(codeKeyword));
} else if (argMultimap.getValue(PREFIX_CREDITS).isPresent()) {
String creditKeyword = ParserUtil.parseCredits(argMultimap.getValue(PREFIX_CREDITS).get()).toString();
predicate = new CreditsContainsKeywordsPredicate(List.of(creditKeyword));
} else {
throw new ParseException(
String.format(MESSAGE_INVALID_COMMAND_FORMAT, FindCommand.MESSAGE_USAGE));
}
return predicate;Design Considerations
This section shares the design considerations we went through during the enhancing the existing find feature.
Aspect: Parsing of composite predicate
The table below shows comparisons between the two approaches.
Approach |
Pros |
Cons |
1. Implement an algorithm Shunting Yard that parses the complex boolean expression and returns a composite predicate. |
Find command can be very flexible. It can work with multiple parameters to search for the specific modules that the user wants. |
|
2. Do an implicit logical |
Very easy to implement |
|
After weighing both pros and cons, we decided to go with approach 1.
As we are expecting many similar names between modules in the university curriculum, if the user could only search
with an implicit logical OR, the user would not be able to find the desired modules effectively. This can drastically
reduce the effectiveness of the find command.